
這次美國總統大選,雖然拜登如預期贏了,但是沒有贏得如預測那麼大。
上次大選民調預測希拉蕊當選結果被翻盤的失準民調,再度成為眾矢之的。
許多人怪罪「隱形的川粉」造成民調失準,也有人說是樣本的空間分佈考量不足。
我不是民調專家,也不知道這些選舉民調背後的方法細節。
不過環境調查和漁業調查也是類似的理論基礎,
也有類似「蓋牌」和「空間分佈不均」的問題,剛好藉此分享,環評怎麼處理
1. 拒答的問題
如果支持川普的人都拒答,那隨機調查出來的結果就會偏向拜登。
其實漁業調查也有這個問題,比方說,不釣魚的人不想回答漁業問卷
所以如果只是用單純隨機分配樣本然後取平均去估計,
那所得到的結果就會偏高(更別提有釣魚的人還喜歡報高的問題)
碰到拒答怎麼辦?
大體上有三個方向:
事前的分層採樣(stratification),
事後的改變配重(weighting),
或是用統計模型的方式去填補未答空白(imputation model)。
但不管是哪一個方法,都要根據觀察不斷調整,才不會失準。
(a) 分層法
改善樣本分配策略,如不愛回答的族群要配多一點的樣本。
比方說我現在做的研究之一,就是用過去觀察觀測資料建一個機器學習模型,去估計該鎮居民在不同的條件下去釣魚的機率分別是多少,然後依此去改變樣本分配的“層”。
有的州可能只有夏天又住得很靠近沿岸時才很可能去釣魚,有的州則十分熱衷水上活動,有釣魚執照的居民一年四季不管多遠都會去釣。
換句話說,每個州的釣魚熱區/冷區的時空分佈不一樣,不能一刀切。
同理,如果川粉傾向拒絕表態,那傳統共和黨區就要分多一點樣本。
而且這個層如果只用州去切可能太粗,如果能做到county甚至zipcode的程度(當然後著就貴多了…), 或是根據過去觀測去評估各州的紅藍區來改善樣本分配,估計應該可以更準。
(b)配重法
配重也是一樣道理,少答的族群難得碰到有回答的,配重要多一點(一人代表比較多人)。
而後續的配重,還可以進一步可以依照性別,種族,等「問了才知道」的資料去進一步調整分析結果,降低偏差。
好比說,根據我們的觀察,年長的白男人,比年輕亞裔女性更可能去釣魚,那這兩個族群的配重就不一樣。
配重的時候,也需要適度揪出離群值,把他的配重調輕。
好比說,一個住離岸200mile又沒有釣魚執照的人,兩個月內去釣魚30次!
除非有很確切的證據指出他說謊,不然原則上我們相信他的答案,不會隨意把樣本刪除,但會把他的比重調輕,變成他只代表他自己,然後把他原有其他的配重平均分給別人。
同理,如果在川粉區好不容易抽到一個願意回答問券的,結果剛好他是世代民主黨死忠支持者,如果沒有考慮離群值的問題,可能就誤以爲那區翻藍了。
這個“適度”真的是關鍵,不能把不符合你預期的每一個值都說他只是例外,否則這個調查結果只是複製你所認為的結果而已。真的需要根據觀察不斷微調修正。
(c)統計模型法
環計調查也常碰到測了但沒有結果,有點類似調查了但拒答的情形。
比方說調查水質的微量重金素時濃度時,常見大半的樣本都是偵測值(DL)以下。
過去的方式常見用0, 或是偵測值的一半(1/2 DL)去填補,更糟是直接刪除,這些做法都會改變distribution & variation。
更精準的方式,是從有觀察到的部分,建一個統計模型(如 maximum likelihood estimation),回推沒觀察到的部分,回推的方式從簡單的回歸分析到機器學習都有。
不管怎麼回推,整體上都會比粗暴刪除或是填入一個主觀的值更精確。
從substitution改成imputation也是我在馬州環保局大力推動的方式分析之一。
我個人喜歡imputation多於weighting多一點,因為改配重常常有讓variance變大的問題,而且要一直改這改那。甚至可以和配重一起雙管齊下,讓分析結果更精準。
2. 空間尺度不平衡問題
傳統的樣本隨機分配,大部分就是配一個數字,然後隨機抽樣。
但如果這些樣本其實有相對的空間資料(如地址, 經緯度),當你再把這些樣本放到地圖上,他們在空間上的分佈不見得是平衡的; 有可能某區一堆樣本,某區很空。
這個問題用arcGIS內建的隨機抽樣無法解決,因為它背後的演算法沒有真的考慮spatial balance。
傳統上就是用分層再分層的方式處理,去確保你要的單位區域有一定的樣本數,分非常多層的時候的確可以減少某區很空曠的問題,但這增加取樣的複雜度,而且在很大的空間尺度時就很有限,難不成你要分20層?
畫格子也是一樣的問題,固然格子切越小越均勻,然而這在很大的空間尺度且目標樣本分佈稀少時,一樣是曠日費時成本效益很低,畢竟不管是人或目標調查物種,很可能都不是均勻的分佈在空間中,好比人可能住在交通幹道附近。
在環境調查中,是可以用 Generalized Random Tessellation Stratified (GRTS, Stevens and Olsen 2004)來達到spatial balance的目的。
用這個方式取代傳統的數字隨機挑樣或是GIS上的內建取樣,也是第二個我在馬州環保局大力推動的優化環境觀測的方向之一。
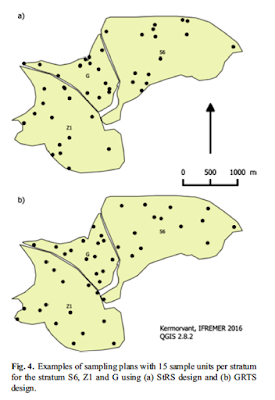
(圖:(a)為傳統分層隨機取樣,可見有些地方樣本擠在一起,有些地方很空曠
(b)為使用GRTS, 隨機與spatial balance兼顧, Kermorvant et al 2017)
再回看民調為什麼不準?
拒答,亂答,或是樣本分配沒有考量空間都是可能的原因。
甚至抽樣的方式可能會有偏差,如 如果是打市內電話,可能都抽到老人,如果都是網路,可能都是年輕人,等等。
不過如果知道差在哪,都是可以藉由不斷觀察不斷修正的。
民調某種程度上比環境觀測等可以直接測量的觀測更複雜(因為牽涉到人,也很難自動化), 這方面的研究也非常多。
不管是民調或環境調查,都跟我以前想像的「隨機取樣取個平均值」很不同。
這篇只有很簡略的大概提一下樣本分配跟簡單分析可能的處理,但還有很多未提的眉角和細節。調查有很多學問,真的是別有洞天!
所以民調和環評的錢不能省啊,好不好~差~很~多~阿!
[更多問卷科學]
參考資料:
- Kermorvant, C., Cailly, N., d’Amico, F., Bru, N., Sanchez, F., Lissardy, M., & Brown, J. (2017). Optimization of a survey using spatially balanced sampling: a single-year application of clam monitoring in the Arcachon Bay (SW France). Aquatic Living Resources, 30, 37.
- Stevens Jr, D. L., & Olsen, A. R. (2004). Spatially balanced sampling of natural resources. Journal of the American statistical Association, 99(465), 262-278.
- Rubin, D. B. (2004). Multiple imputation for nonresponse in surveys (Vol. 81). John Wiley & Sons.
- Newman, D. A. (2003). Longitudinal modeling with randomly and systematically missing data: A simulation of ad hoc, maximum likelihood, and multiple imputation techniques. Organizational Research Methods, 6(3), 328-362.
- Helsel, D. R. (2005). Nondetects and data analysis. Statistics for censored environmental data. Wiley-Interscience.
- Safety, C. P. Science Policy Note: Assigning Values to Nondetected/Nonquantified Pesticide Residues in Food.
我該唸博士班嗎?

博士訓練很不一樣,是訓練你無中生有,從找問對問題、解決問題、創造出新的知識、發表嚴謹的科學報告,這個過程才是精華。出師後,你就是一個獨立的開路人。這個0到1的能力很珍貴,非常有市場價值。
光是問對問題就很不容易,你很可能不會一開始就問對,我在博班問的問題有一半是錯的。走完這一趟會大幅增加你的自我認知,和對世界的理解; 你會更清楚知道自己的定位在哪裡。